Learning-based Robot Navigation
Introduction to Deep Learning
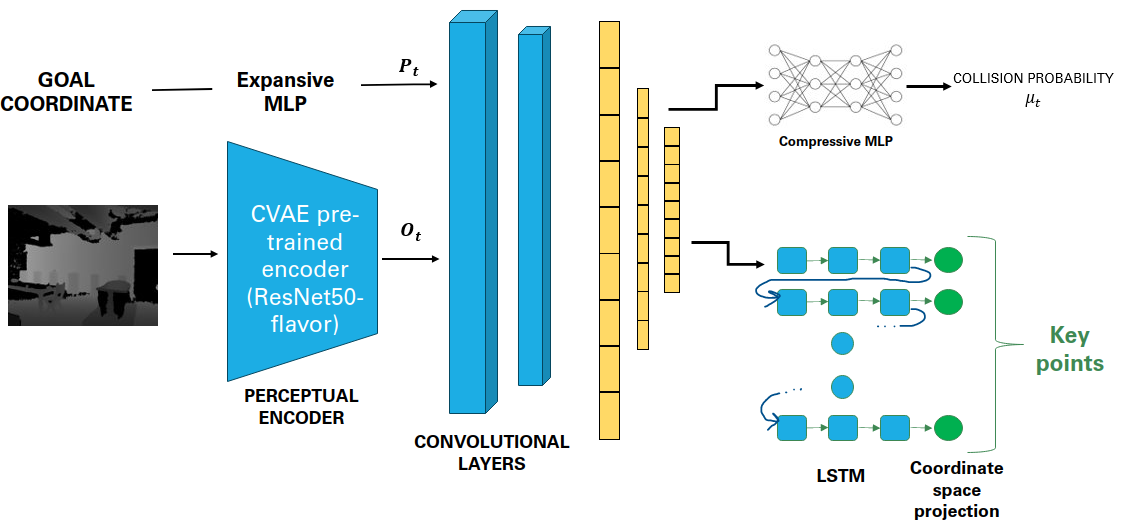
Abstract: We introduce a unified learning-based framework for real-time autonomous navigation in complex environments, integrating perception and path planning into a single pipeline. Building upon the iPlanner, an end-to-end policy planning model originally developed for ground robots, we adapt its Bi-Level Optimization (BLO) process for efficient navigation, creating safe and dynamically feasible trajectories through an improved state representation and incorporating spatiotemporal dependencies within the network. Central to our approach is the application of a pre-trained Convolutional Variational Autoencoder (CVAE) which efficiently extracts crucial features from depth images and simultaneously mitigates high-frequency noise. The low-dimensional rich information is fused with an expanded goal representation to feed downstream planning tasks. We exploit the spatio-temporal sequential nature of the planning task with Long short-term memory (LSTM) networks to generate an extended sequence of keypoint paths. Our loss function uses the optimization process to prioritize the safety and dynamic feasibility of the paths generated. We train our model entirely in simulated environments, employing various data augmentation techniques to reduce the sim2real gap. We present the results of our ablation study for our pre-trained CVAE, trained our end-to-end pipeline, and show comparable results to iPlanner while succeeding in cases where large obstacles are present. Finally, we set the stage for future hardware implementation.
Our sumitted report is available here: Submitted Report
The code repository is available here (fork of baseline): Github Repository - BabyNet
For my Introduction to Deep Learning class project, taught by Pr. Bhiksha Raj, we tackled the improvement of a recent paper (iPlanner paper) for real-time autonomous navigation in complex environments, integrating perception and path planning into a single pipeline. In particular, I focused our efforts on a specific failure case:

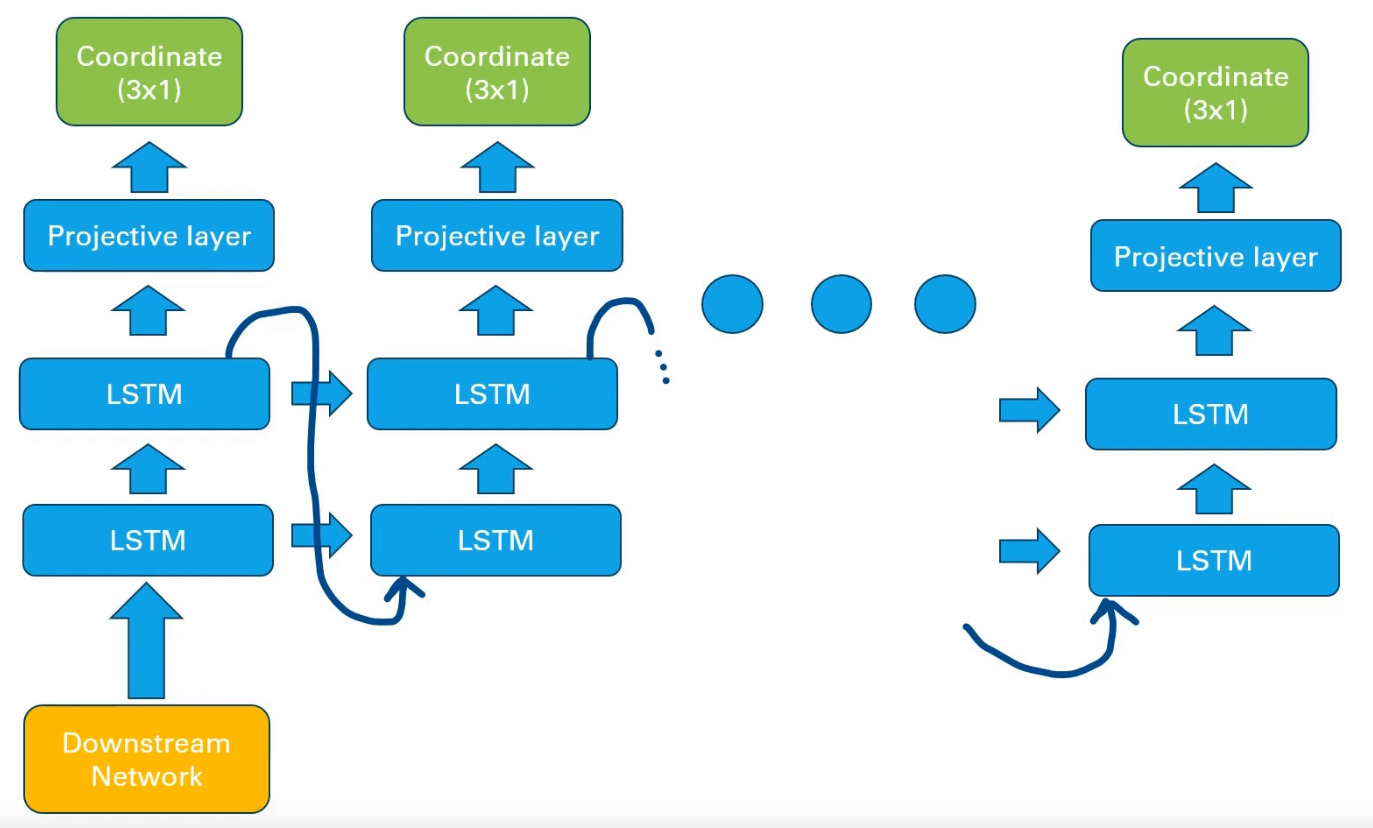
To do so, we tried to improve the state representation within the network as well as incorporating the planning task logic ithin the network. We replaced the decoding block with a pre-trained Convolutional Variational Auto Encoder, providing an effective low-dimensional latent space for feature extraction used by all downstream planning tasks. We representent spatiotemporal dependencies of the planning task through an Long Short-Term Memory-based (LSTM) sequence generator that are then projected to coordinates space.